
Performances
Niveau sonore
Système de refroidissement
Design
Prix
Asus signe une carte d'une qualité de fabrication irréprochable et performante grâce au dernier GPU Nvidia RTX 3080 tout en étant parfaitement bien refroidie et silencieuse même soumise à rude charge. Le seul problème sera de la trouver disponible !
Salut à tous !
Après l’arrivée du ray tracing et du DLSS chez Nvidia et ses premières RTX Turing sorties en 2018, le fondeur revient à l’attaque avec Ampere, une architecture qui promet une grosse augmentation de performance pour un tarif qui ne flambe pas par rapport à la précédente génération. En effet, alors que le MSRP des RTX 2080 Super (et RTX 2080 avant elle) hors FE était de 745 €, les nouvelles RTX 3080 sont supposées démarrer à 719 €. Pour notre dossier, on a récupéré une carte partenaire Asus TUF Gaming RTX 3080 OC, un modèle annoncé à 789 €. Qu’est-ce que la bête a dans le ventre ? C’est ce que nous allons voir !
Ampere
Tout d’abord et premier changement par rapport à Turing, la finesse de gravure passe de 12 nm (TSMC) à 8 nm (Samsung). Cela permet aux puces d’être soit plus petite pour un nombre de transistors identique, soit au contraire dotées de plus de transistors à taille égale, voire les deux en même temps ! C’est exactement le cas pour le GA102 qui équipe les RTX 3080 et 3090, le plus gros DIE grand public à l’heure actuelle.
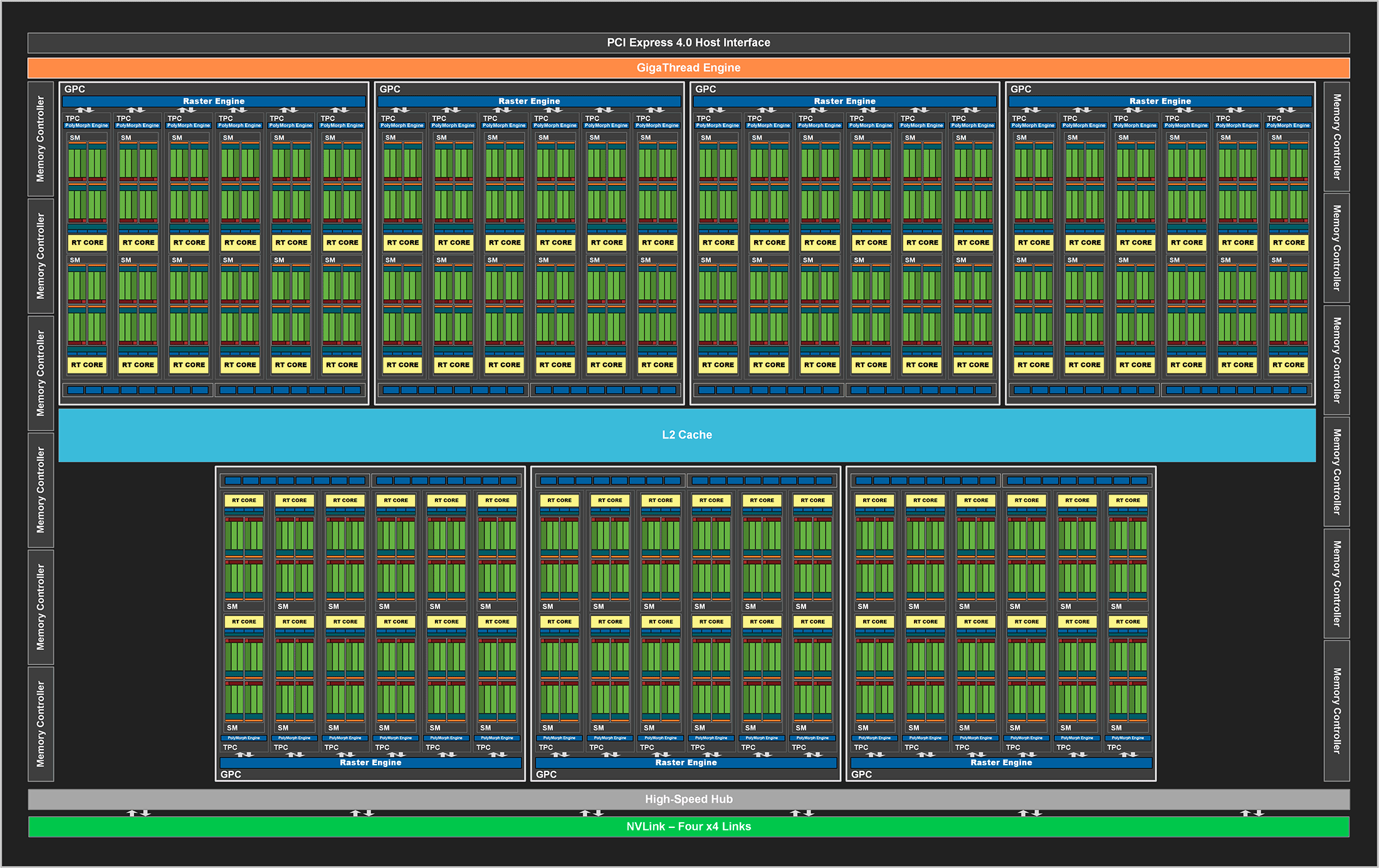
Avec un DIE de 628 mm² pour 28,3 milliards de transistors, c’est un gros modèle mais qui reste plus petit que les 754 mm² (et 18,6 milliards de transistors) pour le TU102 qui équipe les RTX 2080 Ti. Quant aux RTX 2080 Super que la RTX 3080 remplace, le TU104 plafonnait à 545 mm² pour « seulement » 13,6 milliards de transistors. On note donc une grosse amélioration de la densité des composants. Comme on peut le voir sur le diagramme ci-dessus, le GA102 compte un totale de sept GPC, contre six pour Turing et son TU102. Un GPC (Graphics Processing Clusters) est un bloc qui contient les SM, coeurs RT, tensors, coeurs CUDA ainsi que tout récemment les ROPs, on peut le comparer grossièrement à un coeur que l’on retrouve dans les CPU de bureau.
GA102 pas encore complet
| RTX 2080 | RTX 2080 Super | RTX 2080 Ti | RTX 3080 | RTX 3090 | |
| GPU | TU104 | TU104 | TU102 | GA102 | GA102 |
| Finesse de gravure | 12 nm | 12 nm | 12 nm | 8 nm | 8 nm |
| Nombre de transistors | 13,6 milliards | 13,6 milliards | 18,6 milliards | 28,3 milliards | 28,3 milliards |
| Taille du DIE | 545 mm² | 545 mm² | 754 mm² | 628 mm² | 628 mm² |
| SMs | 46 | 48 | 68 | 68 | 82 |
| Coeurs CUDA | 2944 | 3072 | 4352 | 8704 | 10496 |
| Cœurs Tensor | 368 | 384 | 544 | 272 | 328 |
| Coeurs RT | 46 | 48 | 68 | 68 | 82 |
| Fréquence de base | 1515 MHz | 1650 MHz | 1350 MHz | 1440 MHz | 1395 MHz |
| Fréquence boost | 1710 MHz | 1815 MHz | 1545 MHz | 1710 MHz | 1695 MHz |
| Quantité mémoire | 8 Go GDDR6 | 8 Go GDDR6 | 11 Go GDDR6 | 10 Go GDDR6X | 24 Go GDDR6X |
| Fréquence mémoire | 1750 MHz (14 Gbps) | 1937 MHz (15,5 Gbps) | 1750 MHz (14 Gbps) | 1188 MHz (19 Gbps) | 1219 MHz (19,5 Gbps) |
| Interface mémoire | 256 bits | 256 bits | 352 bits | 320 bits | 384 bits |
| TGP | 215 Watts | 250 Watts | 250 Watts | 320 Watts | 350 Watts |
Théoriquement, cela permet au GA102 d’avoir 84 SM pour tout autant de coeurs RT (pour la gestion du ray tracing), mais aucun des GPU présents sur le marché est équipé de ce GA102 totalement débloqué. Même la RTX 3090 qui est pourtant le vaisseau amiral du vert n’accueille que 82 SM. De même, le GA102 des RTX 3080 est encore plus castré car il ne dispose que de 68 SM, soit l’équivalent des anciennes RTX 2080 Ti. Si Nvidia fait avec Ampere ce qu’il a fait avec Turing, on voit sans mal arriver des variantes Super ou Ti situées entre les RTX 3080 et 3090, voire un modèle plus performant que cette dernière exploitant un GA102 complet. Mais seul le temps nous le dira !
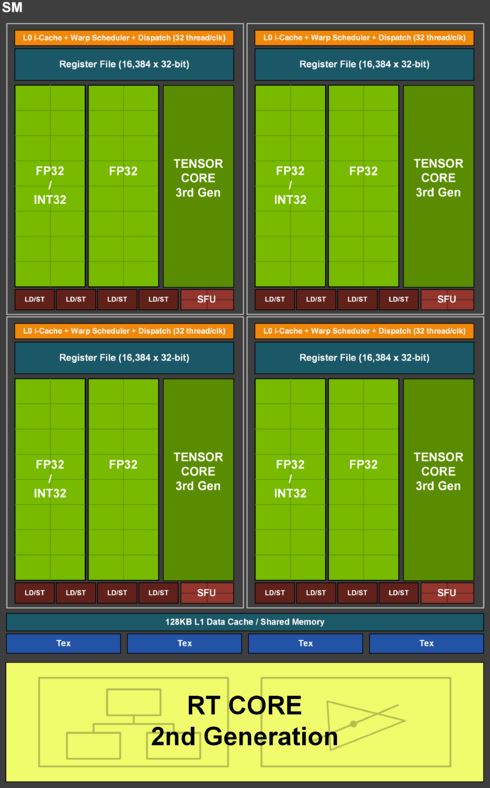
Mais en regardant les caractéristiques techniques, on voit que malgré le nombre de SMs identique entre les RTX 2080 Ti et RTX 3080, Nvidia annonce deux fois plus de coeurs CUDA. Comment est-ce possible ? Le fondeur a doublé pour ce faire le nombre d’unités FP32 au sein de chaque SM. En effet, lorsque Turing disposait de deux blocs distincts, un traitant les entiers (INT32) et l’autre les virgules flottantes (FP32), Ampere propose également deux blocs avec un dédié aux FP32 mais l’autre permet à la fois de traiter les INT32 ainsi que les FP32. Turing a introduit la possibilité de calculer à la fois des INT32 et des FP32 simultanément grâce à des chemins de données distincts. De cette manière, il n’est plus nécessaire de calculer soit un FP32, soit un INT32. Pour Ampere, Nvidia a voulu profiter du chemin de données dédié aux INT32 (qui est loin d’être aussi utilisé que celui des FP32) afin d’augmenter la puissance brute potentielle. Pour ce faire, il a ajouté 64 unités de FP32 (en plus des 64 déjà présents) mais qui partagent le chemin des INT32. Théoriquement donc et si les applications utilisées demandent uniquement des calculs à virgule flottante, la puissance brute est doublée. Si des calculs sur des entiers doivent être faits, cela sera au détriment des FP32 sur ce chemin de données. La valeur données des coeurs CUDA représente donc le meilleur des cas de figure, quand le GPU ne doit traiter que des FP32. Si les unités INT32 et FP32 sont chargées de manière égale (et ce n’est pas gagné), on se retrouve avec un total identique de 4352 FP32 sur les RTX 2080 Ti et 3080, ou 5376 pour un GA102 complet contre 4608 pour un TU102 (Titan RTX) complet.
Coeurs RT et Tensor
Comme pour Turing, Ampere dispose également de coeurs dédiés au traitement du ray tracing, ou coeurs RT. Argument majeur lors de la sortie des premières RTX, Nvidia a travaillé ce point pour Ampere et a apporté un gros boost au niveau des performances de chacun de ces coeurs. Après avoir analysé le fonctionnement de ses coeurs RT dans les jeux, Nvidia a vu que le principal goulot d’étranglement était le traitement des intersections entre les différents rayons et les triangles. Pour remédier au problème, le débit a été double à ce niveau. Cela ne veut pas dire que les performances sont doublées, mais le temps de calcul est grandement amélioré, jusqu’à 70 % selon le fondeur.
Les coeurs Tensors quant à eux ont également été largement revus. Tout d’abord, ils ont été réduit de moitié sur Ampere par rapport à Turing. Mais comme il s’agit d’une architecture différente, il n’est pas possible de comparer aussi facilement la puissance au nombre de coeurs présents. Pour rappel, les coeurs Tensor sont principalement chargés de gérer le DLSS (Deep Learning Super Sampling) dans les jeux pour les joueurs. Ils ont d’autres utilisations possibles bien sûr, mais c’est le DLSS qui sera retenu pour le commun des mortels. Le DLSS permet d’appliquer des textures haute résolution à une scène calculée en plus basse résolution et ainsi augmenter les performances tout en gardant un niveau de détail au moins aussi bon que la résolution native. Par exemple, activer le DLSS en mode qualité en 4K dans les jeux prenant en charge le DLSS 2.0 (Wolfenstein : Youngblood par exemple) fait descendre la résolution en 1440p (2560 x 1440) et le DLSS se charge alors de reconstruire une image visuellement identique (voire meilleure) à la 4K native. En pratique, le gain en FPS est substantiel, jusqu’à 50 % de mieux. Avec les coeurs Tensor de troisième génération (Turing en est déjà à la deuximème génération), Nvidia annonce pouvoir afficher de la 8K (7680 x 4320) avec une base de seulement 2560 x 1400.
Place à la GDDR6X
Après avoir introduit la GDDR6 sur sa génération Turing, Nvidia revient à la charge avec les premières puces de GDDR6X ! Mais ce n’est vrai que pour les GPU les plus haut de gamme RTX 3080 et 3090 pour le moment, les modèles moins performants se contentent pour l’instant de GDDR6. Micron est à l’origine de ces nouvelles puces, la bande passante est en forte augmentation. En effet, on passe de puces GDDR6 14 Gbps sur toutes les RTX sauf la RTX 2080 Super (puces 15,5 Gbps) à 19 Gbps pour la RTX 3080 et 19,5 Gpbs pour la RTX 3090. Avec un bus de 320 bits pour la RTX 3080 (760,3 Go/s), c’est un bon de 53 % de la bande passante disponible par rapport à la RTX 2080 Super (495,9 Go/s) contre 23 % pour la RTX 2080 Ti (616 Go/s). Mais les modules de GDDR6X ne sont pas encore poussés dans leurs retranchement pour l’instant sur les RTX 3000, il existe des modules capables de délivrer 21 Gbps.
Consommation en augmentation
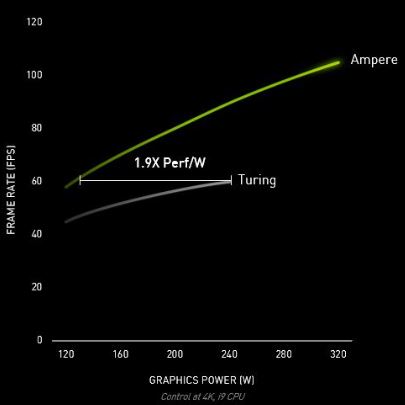
Avec des caractéristiques si différentes entre les « anciennes » RTX 2080 / 2080 Super, à savoir plus du double de transistors pour un GPU encore plus gros, la consommation maximale augmente. En effet, on passe de 215 (2080) et 250 Watts (2080 Super) à 320 Watts ! On passe au-delà de tout ce qui a été présenté jusqu’à présent au niveau des cartes graphiques grand public. Mais si le niveau sonore ainsi que la température n’explosent pas comme on pouvait le voir sur certains GPU par le passé, cela pourrait être acceptable pour ce GPU haut de gamme. Autant faut-il que les performances suivent bien sûr. Si on se trouve face à un GPU consommant 320 Watts dans le pire des cas et qu’il n’est que 28 % plus performant qu’un autre GPU consommant 250 Watts, on n’est pas vraiment face à un rapport performance / consommation plus intéressant. D’après Nvidia, ce rapport serait 1,9 X meilleur sur Ampere par rapport à Turing. Mais ce n’est pas lorsque le GPU est chargé à son maximum, on parle de jeux bridés à 60 FPS (synchronisation verticale) dans les deux cas.




![Photo of [Rumeur] Une première idée des prix des prochains GPU Intel Arc Alchemist ?](https://img.conseil-config.com/2021/01/Asus_Intel_Iris_Xe_featured-220x150.jpg)


Soyez le premier à commenter sur le forum: forum.conseil-config.com